Long Chen
Senior Research Director &
Principal Scientist
Xiaomi

I am a Senior Research Director and Principal Scientist at Xiaomi, where my mission is bringing Artificial Intelligence to the physical world. I lead research in Embodied Intelligence, with a focus on pioneering the next generation of Autonomous Driving and Robotics. My work is at the intersection of Computer Vision, end-to-end learning systems, and Vision-Language-Action (VLA) models, aimed at building intelligent agents that can perceive, reason, and act in complex, real-world environments.
Previously, I was a Staff Scientist at Wayve, where I spearheaded the development of Wayve’s VLA models for the next generation of End-to-End Autonomous Driving. Before that, as a Research Engineer at Lyft Level 5, I led the fleet learning initiative to pretrain the ML planner for Lyft’s self-driving cars using large-scale, crowd-sourced fleet data.
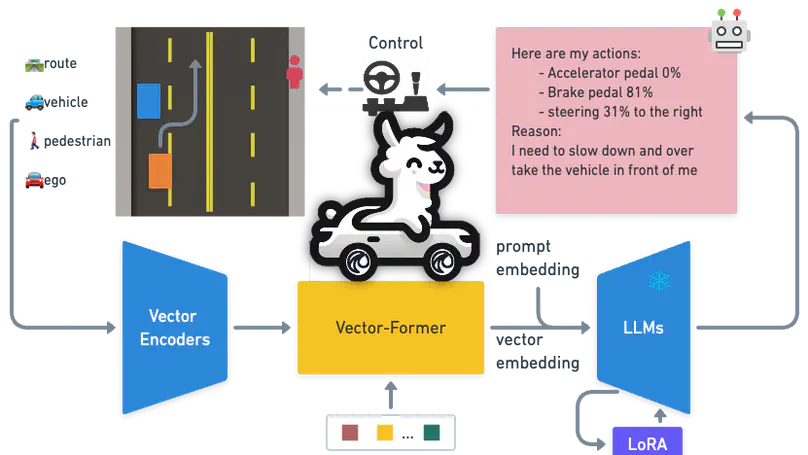
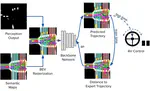
My work Driving-with-LLMs [ICRA 2024, over 250 citations and 500 GitHub stars] was one of the first works on exploring Large Language Models (LLMs) for Autonomous Driving; LINGO [ECCV 2024] is the first VLA end-to-end driving model tested on public roads in London; and SimLingo [CVPR 2025] won 1st place at the CVPR 2024 CARLA Autonomous Driving Challenge. My work has been widely featured in news media, such as Fortune, Financial Times, MIT Technology Review, Nikkei Robotics, and 36kr.
- Artificial Intelligence
- Computer Vision
- Multi-modal Large Language Models (LLMs)
- Robotics
PhD in Computer Vision / Machine Learning, 2015 - 2018
Bournemouth University, UK
MSc in Medical Image Computing, 2013 - 2014
University College London (UCL), UK
BSc in Biomedical Engineering, 2009 - 2013
Dalian University of Technology (DUT), China
Recent News
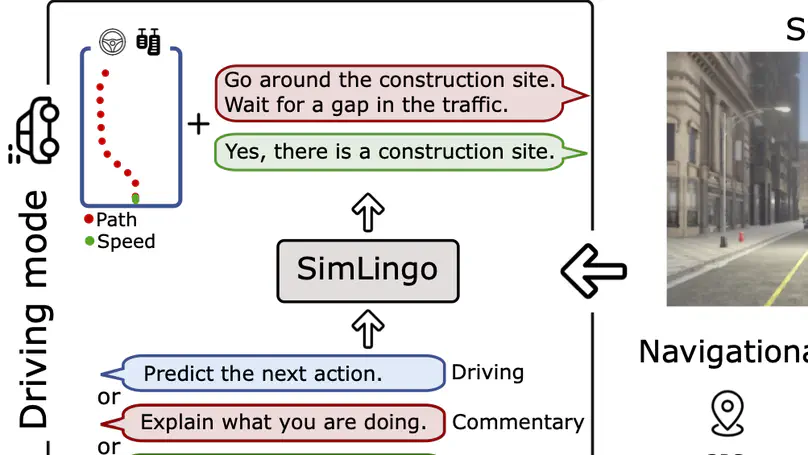
- June 2025: Paper SimLingo:Vision-Only Closed-Loop Autonomous Driving with Language-Action Alignment was accepted to CVPR 2025!
- Sep 2024: Keynote talk at ECCV 2024 Workshop: Autonomous Vehicles meet Multimodal Foundation Models.
- Sep 2024: Keynote talk at IEEE ITSC 2024 Workshop: Large Language and Vision Models for Autonomous Driving.
- Sep 2024: Keynote talk at IEEE ITSC 2024 Workshop: Foundation Models for Autonomous Driving.
- July 2024: Paper LingoQA: Video Question Answering for Autonomous Driving was accepted to ECCV 2024!
- June 2024: Keynote talk at CVPR 2024 Workshop: Vision and Language for Autonomous Driving and Robotics.
- June 2024: Organized the CVPR 2024 Tutorial: End-to-End Autonomy: A New Era of Self-Driving in Seattle, US.
- June 2024: CarLLaVA won the 1st place of CARLA Autonomous Driving Challenge!
- May 2024: Presented the ICRA 2024 Paper: Driving-with-LLMs in Yokohama, Japan.
- June 2023: Organized the ICRA 2023 Workshop on Scalable Autonomous Driving in London, UK.
- June 2021: Co-organized the CVPR 2021 Tutorial: Frontiers in Data-driven Autonomous Driving
- Feb 2021: Granted US patent Guided Batching - a method for building city-scale HD maps for autonomous driving
- June 2021: Two papers, Data-driven Planner and SimNet, got accepted by ICRA 2021
- June 2020: We released the Lyft Level 5 Prediction Dataset
Experience
AV2.0 - building the next generation of self-driving cars with End-to-End (E2E) Machine Learning, Vision-Language-Action (VLA) models.
[CVPR 2024: End-to-End Tutorial] [ICRA 2023: End-to-End Workshop]
Autonomy 2.0 - Data-Driven Planning models for Lyft’s self-driving vehicles.
[CVPR 2021: Autonomy 2.0 Tutorial] [ICRA 2021: Crowd-sourced Data-Driven Planner]