Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving
Abstract
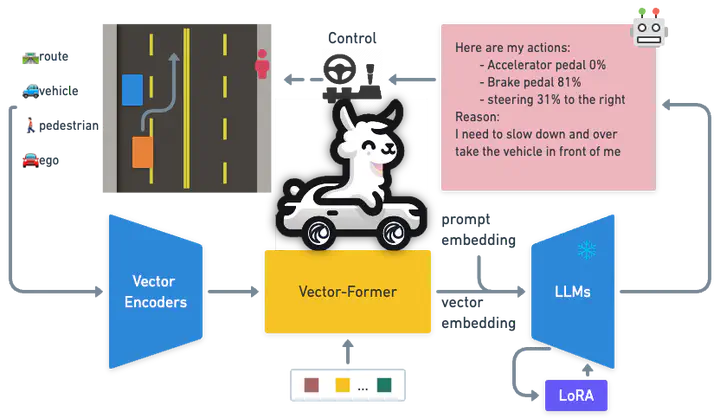
Large Language Models (LLMs) have shown promise in the autonomous driving sector, particularly in generalization and interpretability. We introduce a unique object-level multimodal LLM architecture that merges vectorized numeric modalities with a pre-trained LLM to improve context understanding in driving situations. We also present a new dataset of 160k QA pairs derived from 10k driving scenarios, paired with high quality control commands collected with RL agent and question answer pairs generated by teacher LLM (GPT-3.5). A distinct pretraining strategy is devised to align numeric vector modalities with static LLM representations using vector captioning language data. We also introduce an evaluation metric for Driving QA and demonstrate our LLM-driver’s proficiency in interpreting driving scenarios, answering questions, and decision-making. Our findings highlight the potential of LLM-based driving action generation in comparison to traditional behavioral cloning. We make our benchmark, datasets, and model available for further exploration.