Self-supervised monocular image depth learning and confidence estimation
Abstract
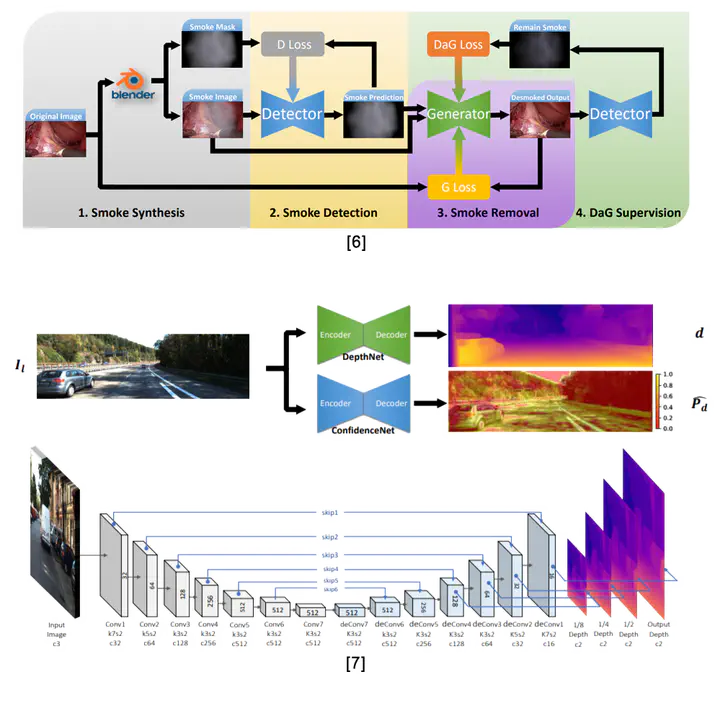
We present a novel self-supervised framework for monocular image depth learning and confidence estimation. Our framework reduces the amount of ground truth annotation data required for training Convolutional Neural Networks (CNNs), which is often a challenging problem for the fast deployment of CNNs in many computer vision tasks. Our DepthNet adopts a novel fully differential patch-based cost function through the Zero-Mean Normalized Cross Correlation (ZNCC) to take multi-scale patches as matching and learning strategies. This approach greatly increases the accuracy and robustness of the depth learning. Whilst the proposed patch-based cost function naturally provides a 0-to-1 confidence, it is then used to self-supervise the training of a parallel network for confidence map learning and estimation by exploiting the fact that ZNCC is a normalized measure of similarity which can be approximated as the confidence of the depth estimation. Therefore, the proposed corresponding confidence map learning and estimation operate in a self-supervised manner and is a parallel network to the DepthNet. Evaluation on the KITTI depth prediction evaluation dataset and Make3D dataset show that our method outperforms the state-of-the-art results.